66 lines
5.9 KiB
Markdown
66 lines
5.9 KiB
Markdown
|
|
---
|
||
|
|
title: Principal Component Analysis
|
||
|
|
---
|
||
|
|
## Principal Component Analysis (PCA)
|
||
|
|
|
||
|
|
### What is it?
|
||
|
|
|
||
|
|
Principal Component Analysis (PCA) is an algorithm used in machine learning to reduce the dimensions of a dataset. You might reduce a dataset containing hundreds of different features to a new dataset containing only two.
|
||
|
|
|
||
|
|
For example, imagine you want to measure a pilot's ability. There are many different factors involved in this. Two relevant features to take into account might be the pilot's skill and the pilot's enjoyment. This would be a two-dimensional dataset, since it contains two features. PCA could reduce these features into one by fusing them together. You might call this new feature "pilot aptitude". This new feature gives you a simpler metric to measure a pilot's ability.
|
||
|
|
|
||
|
|
If you plot pilot skill against pilot enjoyment, you might get something like this:
|
||
|
|
|
||
|
|

|
||
|
|
|
||
|
|
Intuitively, what PCA does is it finds the best straight line (or plane, in higher dimensional situations) on which to project these two features. Projection is done by drawing a perpendicular line between the point and the line. You can see an illustration of this below:
|
||
|
|
|
||
|
|
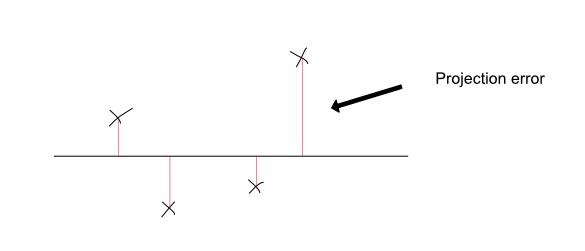
|
||
|
|
|
||
|
|
You can think of PCA as finding the best line for the dataset so that each point's information is better preserved. It does this by minimizing the sum of the squared projection errors of each point. The projection error is the length of the perpendicular lines projecting each point onto the line. By minimizing these, you ensure that the chosen straight line is the best combination of these two features.
|
||
|
|
|
||
|
|
Below are examples of a good line on which to project the data, and a bad one. The good line's resulting projections are more representative of the original data, and have smaller errors. The bad line's resulting projections are clearly a worse representation, and the projection errors are much larger.
|
||
|
|
|
||
|
|

|
||
|
|
|
||
|
|
**Important**: It is worth noting that PCA is different from [linear regression](https://en.wikipedia.org/wiki/Linear_regression). Their optimization objectives (what they aim to minimize) are different.
|
||
|
|
|
||
|
|
If you run PCA on the pilot dataset, you may get a new feature, "pilot aptitude", that looks something like this:
|
||
|
|
|
||
|
|

|
||
|
|
|
||
|
|
The mathematics behind PCA is somewhat complicated, but you don't have to be an expert on it to be able to use it. Even though there is a lot of linear algebra behind it, using it is relatively easy. This is because there are plenty of code libraries with ready-made PCA implementations. A few examples include:
|
||
|
|
- [A JavaScript PCA implementation](https://github.com/mljs/pca).
|
||
|
|
- [Python scikit-learn implementation](http://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html).
|
||
|
|
- [MATLAB implementation](https://www.mathworks.com/help/stats/pca.html).
|
||
|
|
|
||
|
|
|
||
|
|
### Why use it?
|
||
|
|
|
||
|
|
There are many reasons to use the PCA algorithm. One very important one is to visualize data. It is easy to visualize 1-D, 2-D, and even 3-D data, but beyond that, it becomes hard. In machine learning, it is often very useful to visualize the data before beginning to work on it. But a high-dimensional dataset is very hard to visualize. By using PCA, a hundred-dimensional dataset might be reduced to a 2 dimensional one.
|
||
|
|
|
||
|
|
This is especially useful in real-world situations, where datasets are often high-dimensional. For example, you might be able to combine economic performance metrics like GDP, HDI, etc, into a single feature. This enables you to make better comparisons between countries, and it also allows you to visualize the data using a graph.
|
||
|
|
|
||
|
|
Another reason for using the PCA algorithm is to make your dataset smaller. For problems involving hundreds of thousands of features (like image processing), machine learning algorithms can take a long time to run. By reducing the number of features, you might improve the speed of these algorithms without sacrificing accuracy. You might also save a lot of disk space, especially if you are working with huge datasets.
|
||
|
|
|
||
|
|
### Limitations
|
||
|
|
|
||
|
|
Since you are basically simplifying a dataset when you run PCA, some details may be lost in the process. This is especially the case with data points that are very spread out and do not have a very strong correlation.
|
||
|
|
|
||
|
|
|
||
|
|
#### Suggested Reading:
|
||
|
|
<!-- Please add any articles you think might be helpful to read before writing the article -->
|
||
|
|
|
||
|
|
- https://www.reddit.com/r/datascience/comments/668pp1
|
||
|
|
- https://en.wikipedia.org/wiki/Principal_component_analysis
|
||
|
|
- http://www.cs.otago.ac.nz/cosc453/student_tutorials/principal_components.pdf
|
||
|
|
- http://setosa.io/ev/principal-component-analysis/ (Interactive)
|
||
|
|
|
||
|
|
Wikipedia Says, "Principal component analysis (PCA) is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components (or sometimes, principal modes of variation)."
|
||
|
|
|
||
|
|
Principal component analysis(PCA) is a statistical technique used to examine the interrelations among a set of variables in order to identify the underlying structure of those variables. PCA usually reduces the number of features from N-Dimensional to k-Dimensional where k < N
|
||
|
|
|
||
|
|
PCA has following applications :
|
||
|
|
1) Compression: Increase the computational speed and also to reduce storage space
|
||
|
|
2) Visualization: PCA can reduce the data to two or three dimensional data for visualization purpose
|