9.8 KiB
| title | localeTitle |
|---|---|
| Deep Learning | Глубокое обучение |
Глубокое обучение
Глубокое обучение относится к методу машинного обучения, где у вас много искусственных нейронных сетей, сложенных вместе в некоторой архитектуре.
Для непосвященных искусственный нейрон в основном является математической функцией. И нейронные сети - нейроны, связанные друг с другом. Таким образом, в глубоком обучении у вас много математических функций, уложенных сверху (или сбоку) друг в друга в некоторой архитектуре. Каждая из математических функций может иметь свои собственные параметры (для примера уравнение линии y = mx + c имеет 2 параметра m и c ), которые необходимо изучить (во время обучения). После изучения данной задачи (скажем, для классификации кошек и собак) этот стек математических функций (нейронов) готов выполнять свою работу по классификации изображений кошек и собак.
Почему это очень важно?
Выполнение набора правил вручную для некоторых задач может быть очень сложным (хотя теоретически возможно). Например, если вы попытаетесь написать ручной набор правил, чтобы классифицировать изображение (в основном кучу значений пикселей), принадлежит ли оно кошке или собаке, вы поймете, почему это сложно. Добавьте к этому тот факт, что собаки и кошки бывают разных форм, размеров и цветов, и, не говоря уже, изображения могут иметь разные фоны. Вы можете быстро понять, почему кодирование такой простой проблемы может быть проблематичным.
Глубокое обучение помогает решить эту проблему при определении набора правил, которые могут классифицировать изображение как изображение кошки или собаки, автоматически! Все, что ему нужно, это куча изображений, которые уже правильно классифицированы как кошка или собака, и она сможет изучить требуемый набор правил. Магия!
Оказывается, есть много проблем, которые не связаны с изображением (например, распознавание голоса), когда поиск набора правил очень сложный. Глубокое обучение может помочь в этом, если имеется много помеченных данных.
Как тренировать модель глубокого обучения?
Обучение глубокой нейронной сети (так же, как наш набор математических функций, расположенных в некоторой архитектуре) - это в основном искусство с множеством гиперпараметров. Гипер-параметры - это, в основном, такие вещи, как математическая функция, которую нужно использовать, или какую архитектуру использовать, которую нужно вручную отображать, пока ваша сеть не сможет успешно классифицировать кошек и собак. Чтобы тренироваться, вам нужно много помеченных данных (в этом случае много изображений, уже классифицированных как кошки или собаки) и много вычислительной мощности и терпения!
Для обучения вам предоставляется нейронная сеть с функцией потерь, которая в основном говорит о том, насколько отличаются результаты нейронной сети и правильные ответы. В зависимости от значения функции потерь вы изменяете параметры математической функции таким образом, чтобы в следующий раз, когда ваша сеть пытается классифицировать одно и то же изображение, значение функции потерь ниже. Вы продолжаете находить значение функции потерь и обновлять параметры снова и снова по всему набору учебных данных до тех пор, пока значения функции потерь не окажутся в разумных пределах. Ваша массивная нейронная сеть готова!
Некоторые стандартные архитектуры нейронной сети
За последние несколько лет некоторые из моделей (т.е. сочетание математических функций, архитектуры и параметров) стали стандартными для определенных задач. Например, модель под названием Resnet-152 выиграла Imagenet Challenge в 2015 году, которая включает в себя попытку классифицировать изображения на 1000 категорий (включая кошек и собак). Если вы планируете выполнять подобные задачи, рекомендуется начать с таких стандартных моделей и настроить их, если они не соответствуют вашим требованиям.
Модель resnet-152 выглядит так: «Не волнуйтесь, если вы этого не понимаете. Это просто куча математических функций, уложенных друг на друга каким-то интересным образом):
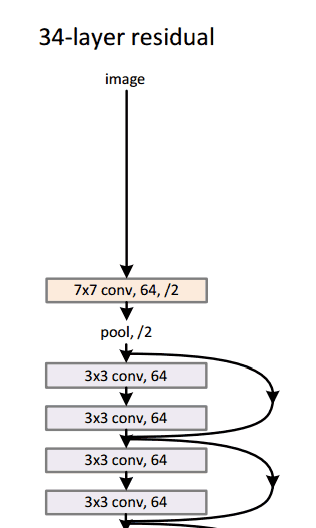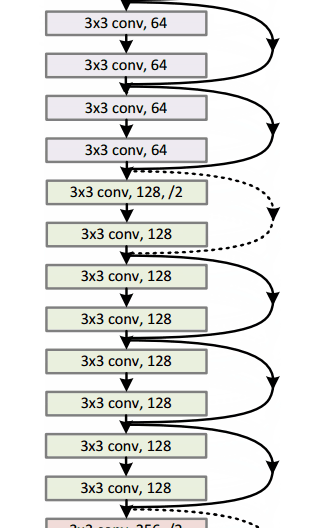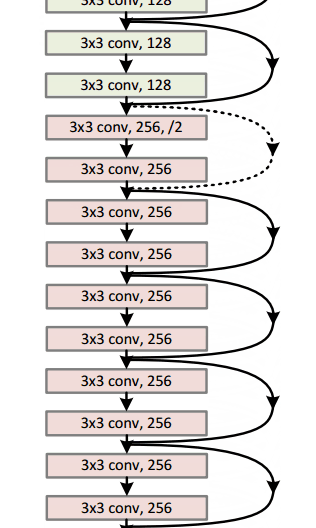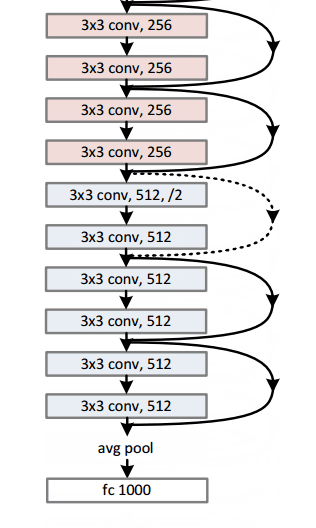
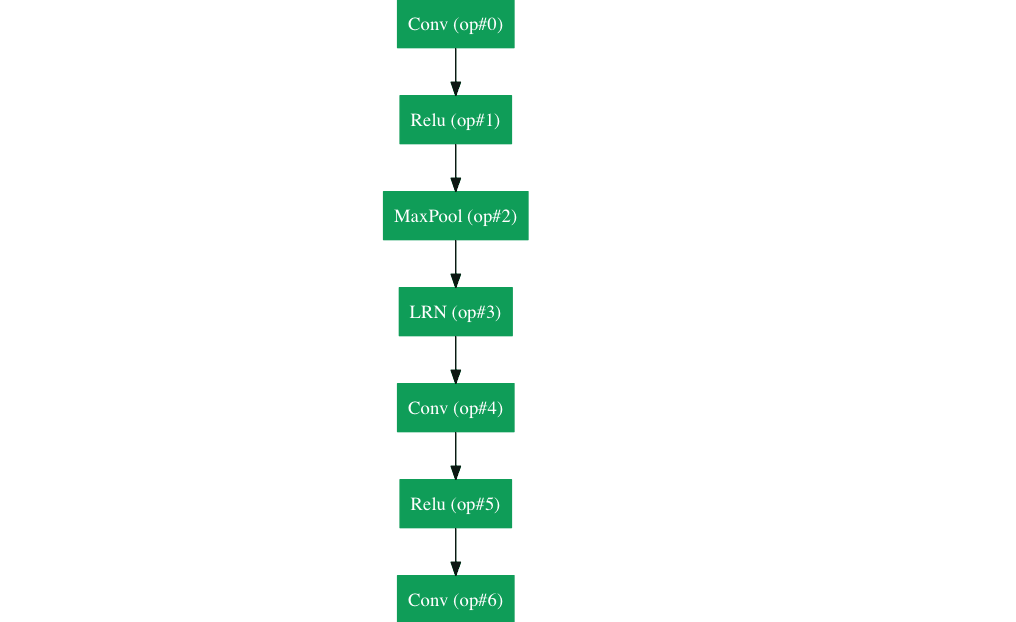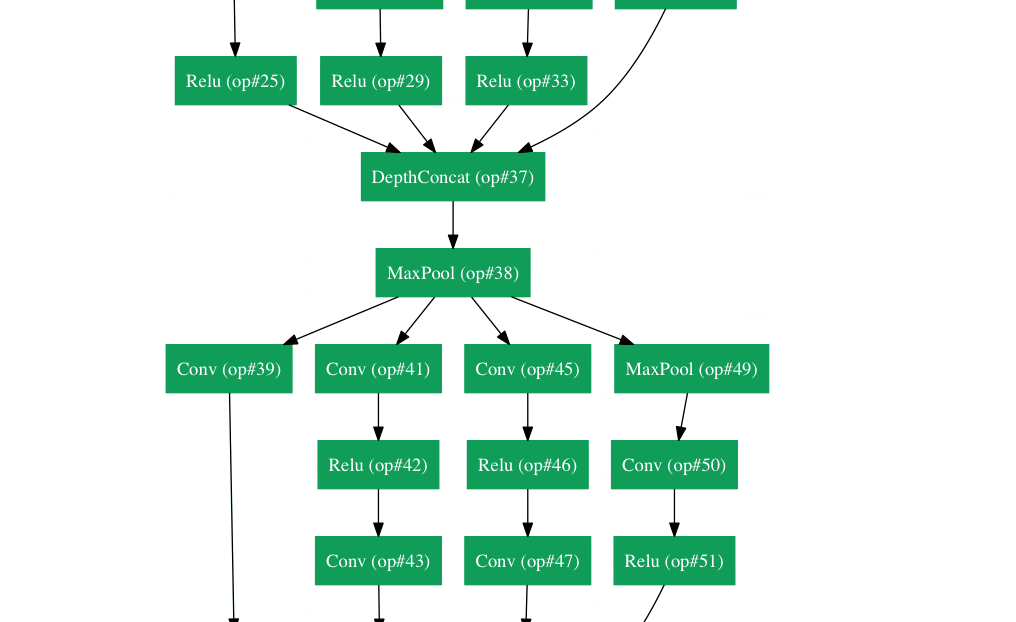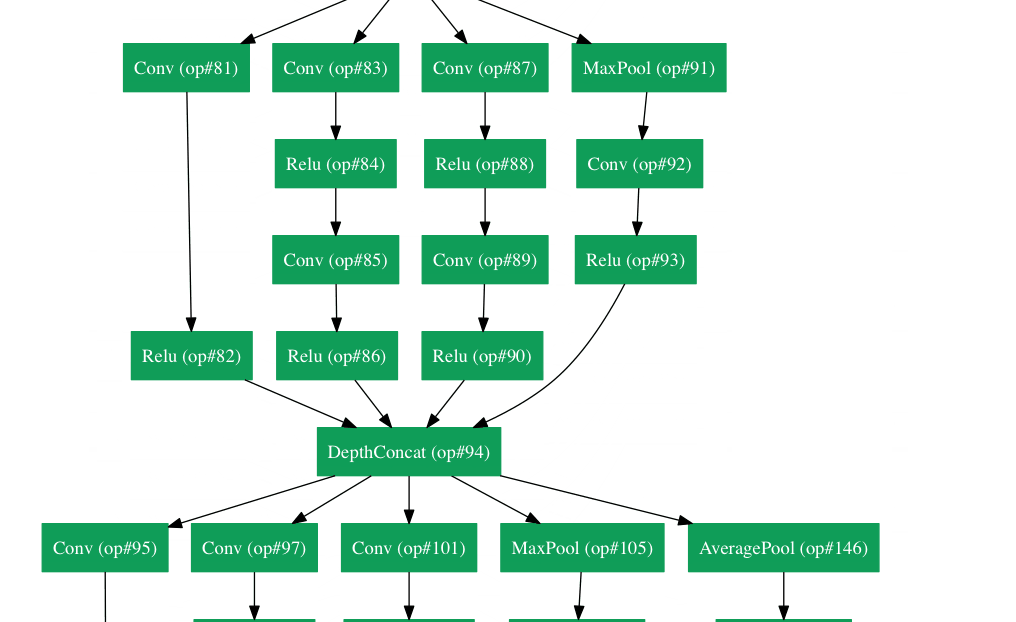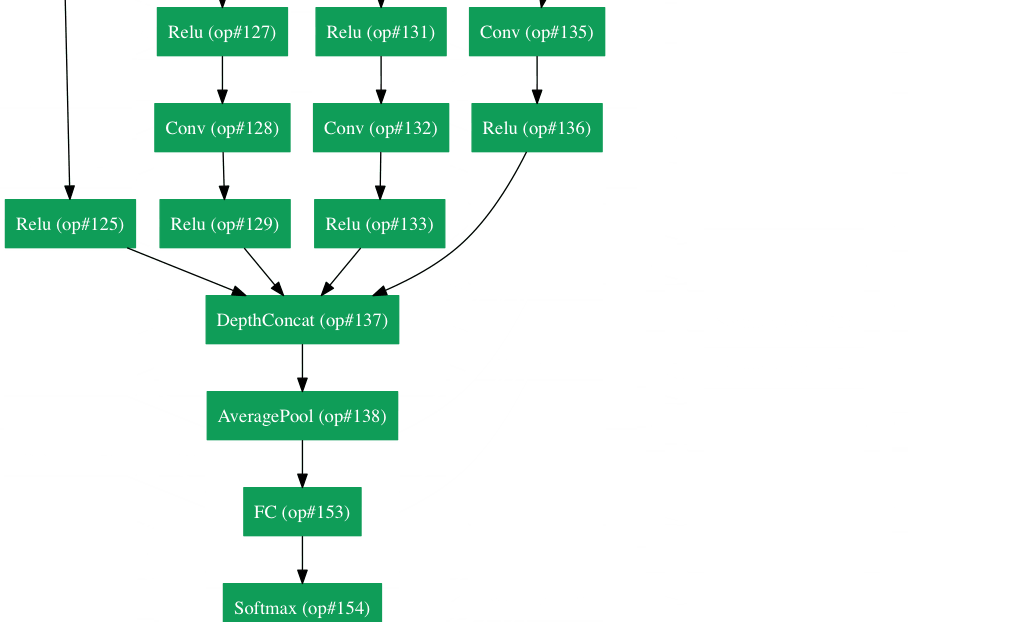
У Google была своя собственная нейронная сетевая архитектура, которая выиграла Imagenet, спровоцированную в 2014 году. Что можно увидеть в gif здесь более подробно .
{kind=link}
Как реализовать свои собственные?
В наши дни существует множество рамок глубокого обучения, которые позволяют вам указать, какую математическую функцию вы хотите использовать, какую архитектуру для ваших функций и какую функцию потерь использовать для обучения. Поскольку обучение такой модели очень интенсивно вычислительно, большинство этих фреймворков генерируют код, оптимизированный для любого оборудования, которое у вас может быть. Некоторые из известных рамок: