62 lines
8.4 KiB
Markdown
62 lines
8.4 KiB
Markdown
---
|
||
title: Principal Component Analysis
|
||
localeTitle: تحليل المكونات الرئيسية
|
||
---
|
||
## تحليل المكون الرئيسي (PCA)
|
||
|
||
### ما هذا؟
|
||
|
||
التحليل الأساسي للعناصر (PCA) هو خوارزمية تستخدم في التعلم الآلي لتقليل أبعاد مجموعة البيانات. قد تقلل مجموعة بيانات تحتوي على مئات الميزات المختلفة إلى مجموعة بيانات جديدة تحتوي على اثنتين فقط.
|
||
|
||
على سبيل المثال ، تخيل أنك تريد قياس قدرة الطيار. هناك العديد من العوامل المختلفة التي ينطوي عليها هذا. هناك ميزتان مهمتان يجب أخذهما بعين الاعتبار قد يكونان مهارة الطيار واستمتاع الطيار. هذا من شأنه أن يكون مجموعة بيانات ثنائية الأبعاد ، لأنه يحتوي على ميزتين. يمكن أن يقلل PCA هذه الميزات في واحد عن طريق دمجها معًا. يمكنك الاتصال بهذه الميزة الجديدة "aibitude pilot". تمنحك هذه الميزة الجديدة مقياسًا أبسط لقياس قدرة الطيار.
|
||
|
||
إذا كنت تخطط لمهارة تجريبية ضد التمتع الطيار ، قد تحصل على شيء من هذا القبيل:
|
||
|
||

|
||
|
||
بشكل حدسي ، ما يفعله PCA هو أنه يجد أفضل خط مستقيم (أو مستوي ، في حالات أبعاد أعلى) لإظهار هاتين الميزتين. يتم الإسقاط عن طريق رسم خط عمودي بين النقطة والخط. يمكنك رؤية مثال على هذا أدناه:
|
||
|
||
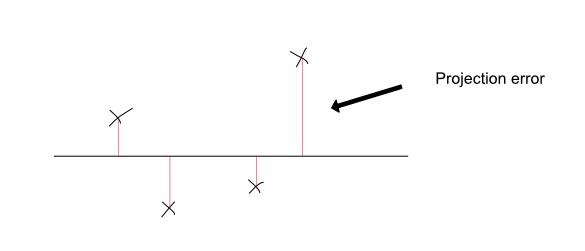
|
||
|
||
يمكنك التفكير في PCA كإيجاد أفضل خط لمجموعة البيانات بحيث يتم الحفاظ على معلومات كل نقطة بشكل أفضل. يقوم بذلك عن طريق تقليل مجموع أخطاء الإسقاط المربعة لكل نقطة. الخطأ الإسقاط هو طول الخطوط العمودية التي تحدد كل نقطة على الخط. من خلال تقليل هذه ، تأكد من أن الخط المستقيم المختار هو أفضل مزيج من هاتين الميزتين.
|
||
|
||
في ما يلي أمثلة لخط جيد يمكنك من خلاله عرض البيانات ، والبيانات السيئة. تعتبر الإسقاطات الناتجة عن الخط الجيد أكثر تمثيلاً للبيانات الأصلية ، ولها أخطاء أصغر. من الواضح أن الإسقاطات الناتجة عن الخط السيئ تمثل تمثيل أسوأ ، وأخطاء الإسقاط أكبر من ذلك بكثير.
|
||
|
||

|
||
|
||
**هام** : تجدر الإشارة إلى أن PCA يختلف عن [الانحدار الخطي](https://en.wikipedia.org/wiki/Linear_regression) . تختلف أهداف التحسين الخاصة بهم (ما يهدفون إلى تقليله).
|
||
|
||
إذا قمت بتشغيل PCA على مجموعة البيانات التجريبية ، فقد تحصل على ميزة جديدة ، "aptitude pilot" ، والتي تبدو كالتالي:
|
||
|
||

|
||
|
||
إن رياضيات PCA معقدة بعض الشيء ، لكن ليس من الضروري أن تكون خبيرًا في ذلك حتى تتمكن من استخدامها. على الرغم من وجود الكثير من الجبر الخطي وراءه ، إلا أن استخدامه سهل نسبيًا. هذا لأن هناك الكثير من مكتبات الأكواد مع تطبيقات PCA الجاهزة. تتضمن بعض الأمثلة ما يلي:
|
||
|
||
* [تطبيق جافا سكريبت PCA](https://github.com/mljs/pca) .
|
||
* [بايثون scikit - تعلم التنفيذ](http://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html) .
|
||
* [تنفيذ MATLAB](https://www.mathworks.com/help/stats/pca.html) .
|
||
|
||
### لماذا استخدامها؟
|
||
|
||
هناك العديد من الأسباب لاستخدام خوارزمية PCA. واحد مهم جدا واحد هو تصور البيانات. من السهل تصور البيانات ثنائية وثلاثية الأبعاد وحتى البيانات ثلاثية الأبعاد ، ولكن بعد ذلك ، يصبح الأمر صعبًا. في التعلم الآلي ، غالباً ما يكون من المفيد جداً رؤية البيانات قبل البدء في العمل عليها. لكن من الصعب جدًا رؤية مجموعة بيانات عالية الأبعاد. باستخدام PCA ، قد يتم تخفيض مجموعة البيانات مائة الأبعاد إلى واحد 2 الأبعاد.
|
||
|
||
هذا مفيد بشكل خاص في حالات العالم الحقيقي ، حيث تكون مجموعات البيانات في كثير من الأحيان عالية الأبعاد. على سبيل المثال ، قد تتمكن من الجمع بين مقاييس الأداء الاقتصادي مثل إجمالي الناتج المحلي ، أو مؤشر التنمية البشرية ، إلخ ، في ميزة واحدة. يمكّنك هذا من إجراء مقارنات أفضل بين البلدان ، كما يسمح لك بتصور البيانات باستخدام الرسم البياني.
|
||
|
||
سبب آخر لاستخدام خوارزمية PCA هو جعل مجموعة البيانات الخاصة بك أصغر. بالنسبة للمشاكل المتعلقة بمئات الآلاف من الميزات (مثل معالجة الصور) ، يمكن أن تستغرق خوارزميات تعلم الآلة وقتًا طويلاً للتشغيل. من خلال تقليل عدد الميزات ، يمكنك تحسين سرعة هذه الخوارزميات دون التضحية بالدقة. يمكنك أيضًا توفير الكثير من مساحة القرص ، خاصةً إذا كنت تعمل مع مجموعات بيانات ضخمة.
|
||
|
||
### محددات
|
||
|
||
نظرًا لأنك تقوم في الأساس بتبسيط مجموعة بيانات عند تشغيل PCA ، فقد تفقد بعض التفاصيل في العملية. هذا هو الحال خاصة مع نقاط البيانات التي تنتشر بشكل كبير وليس لديها علاقة قوية جدا.
|
||
|
||
#### واقترح ريدينج:
|
||
|
||
* https://www.reddit.com/r/datascience/comments/668pp1
|
||
* https://en.wikipedia.org/wiki/ تحليل _المكون الرئيسي_
|
||
* http://www.cs.otago.ac.nz/cosc453/student _tutorials / principal_ components.pdf
|
||
* http://setosa.io/ev/principal-component-analysis/ (Interactive)
|
||
|
||
تقول ويكيبيديا ، "تحليل المكون الرئيسي (PCA) هو إجراء إحصائي يستخدم تحويلًا متعامدًا لتحويل مجموعة من المشاهدات للمتغيرات المرتبطة المحتملة إلى مجموعة من القيم للمتغيرات غير المترابطة خطيًا والتي تدعى المكونات الأساسية (أو في بعض الأحيان ، صيغ التباين الرئيسية) ".
|
||
|
||
التحليل الأساسي للمكونات (PCA) هو أسلوب إحصائي يستخدم لفحص العلاقات المتبادلة بين مجموعة من المتغيرات من أجل تحديد البنية الأساسية لتلك المتغيرات. عادة ما يقلل PCA عدد الميزات من N-Dimensional إلى k-Dimensional حيث k <N
|
||
|
||
لدى PCA التطبيقات التالية: 1) الضغط: زيادة السرعة الحسابية وأيضا لتقليل مساحة التخزين 2) التصور: يمكن PCA تقليل البيانات إلى بيانات ثنائية أو ثلاثية لغرض التصور |