6.3 KiB
| title | localeTitle |
|---|---|
| Deep Learning | Aprendizaje profundo |
Aprendizaje profundo
Aprendizaje profundo se refiere a una técnica en Aprendizaje automático en la que tiene muchas redes neuronales artificiales apiladas en alguna arquitectura.
Para los no iniciados, una neurona artificial es básicamente una función matemática de algún tipo. Y las redes neuronales son neuronas conectadas entre sí. Así que en el aprendizaje profundo, tienes muchas funciones matemáticas apiladas una encima de la otra (o al costado) una de otra en alguna arquitectura. Cada una de las funciones matemáticas puede tener sus propios parámetros (para una instancia, una ecuación de una línea y = mx + c tiene 2 parámetros m y c ) que deben aprenderse (durante el entrenamiento). Una vez aprendido para una tarea determinada (por ejemplo, para clasificar gatos y perros), este conjunto de funciones matemáticas (neuronas) está listo para realizar su trabajo de clasificación de imágenes de gatos y perros.
¿Por qué es un gran problema?
Crear un conjunto de reglas manualmente para algunas de las tareas puede ser muy complicado (aunque teóricamente posible). Por ejemplo, si intentas escribir un conjunto manual de reglas para clasificar una imagen (básicamente un grupo de valores de píxeles) de si pertenece a un gato o un perro, verás por qué es complicado. Agregue a eso el hecho de que los perros y gatos vienen en una variedad de formas, tamaños y colores y, por no mencionar, las imágenes pueden tener diferentes fondos. Puede comprender rápidamente por qué la codificación de un problema tan simple puede ser problemático.
El Aprendizaje profundo ayuda a resolver este problema de averiguar el conjunto de reglas que pueden clasificar una imagen como la de un gato o un perro, ¡automáticamente! Todo lo que necesita es un montón de imágenes que ya están clasificadas correctamente como las de un gato o un perro y podrá aprender el conjunto de reglas requerido. ¡Magia!
Resulta que hay un montón de problemas que no están relacionados con la imagen (como el reconocimiento de voz), donde encontrar el conjunto de reglas es muy complicado. Aprendizaje profundo puede ayudar con eso siempre que haya muchos datos etiquetados ya presentes.
¿Cómo entrenar un modelo de aprendizaje profundo?
El entrenamiento de una red neuronal profunda (también conocida como nuestra pila de funciones matemáticas dispuestas en alguna arquitectura) es básicamente un arte con muchos hiper parámetros. Los hiperparámetros son básicamente cosas tales como qué función matemática usar, o qué arquitectura usar, que debe calcular manualmente hasta que su red pueda clasificar con éxito gatos y perros. Para entrenar, necesitas muchos datos etiquetados (en este caso, muchas imágenes ya clasificadas como perros o gatos) y mucha potencia de computación y paciencia.
Para entrenar, proporciona una red neuronal con una función de pérdida que básicamente dice qué tan diferentes son los resultados de la red neuronal frente a las respuestas correctas. Dependiendo del valor de la función de pérdida, usted cambia los parámetros de la función matemática de tal manera que la próxima vez que su red intente clasificar la misma imagen, el valor de la función de pérdida será menor. Continúa encontrando el valor de la función de pérdida y actualizando los parámetros una y otra vez en todo el conjunto de datos de entrenamiento hasta que los valores de la función de pérdida estén dentro de los márgenes razonables. ¡Tu red neuronal masiva ya está lista!
Algunas arquitecturas de redes neuronales estándar
En los últimos años, algunos de los modelos (es decir, la combinación de las funciones matemáticas, la arquitectura y los parámetros) se han convertido en estándar para ciertas tareas. Por ejemplo, un modelo llamado Resnet-152 ganó el Desafío Imagenet en 2015, que consiste en tratar de clasificar las imágenes en 1000 categorías (gatos y perros incluidos). Si planea realizar tareas similares, la recomendación es comenzar con dichos modelos estándar y modificarlos si no cumplen con sus requisitos.
Un modelo resnet-152 se ve así (no te preocupes si no lo entiendes. Es solo un montón de funciones matemáticas apiladas una encima de la otra de una manera interesante):
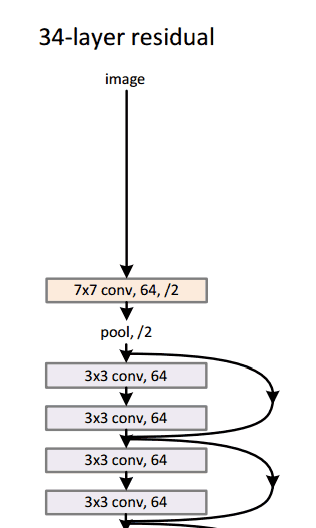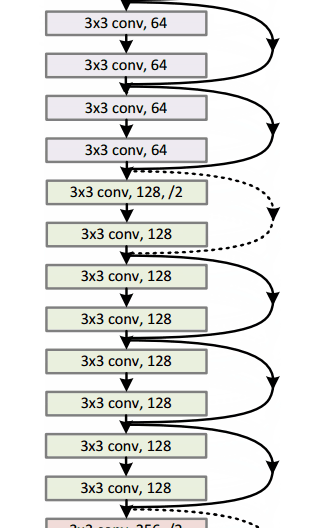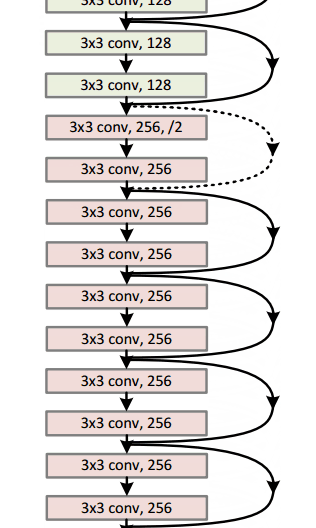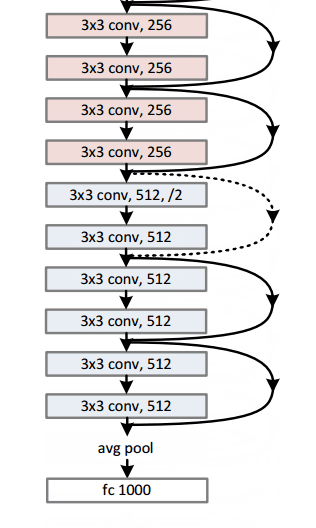
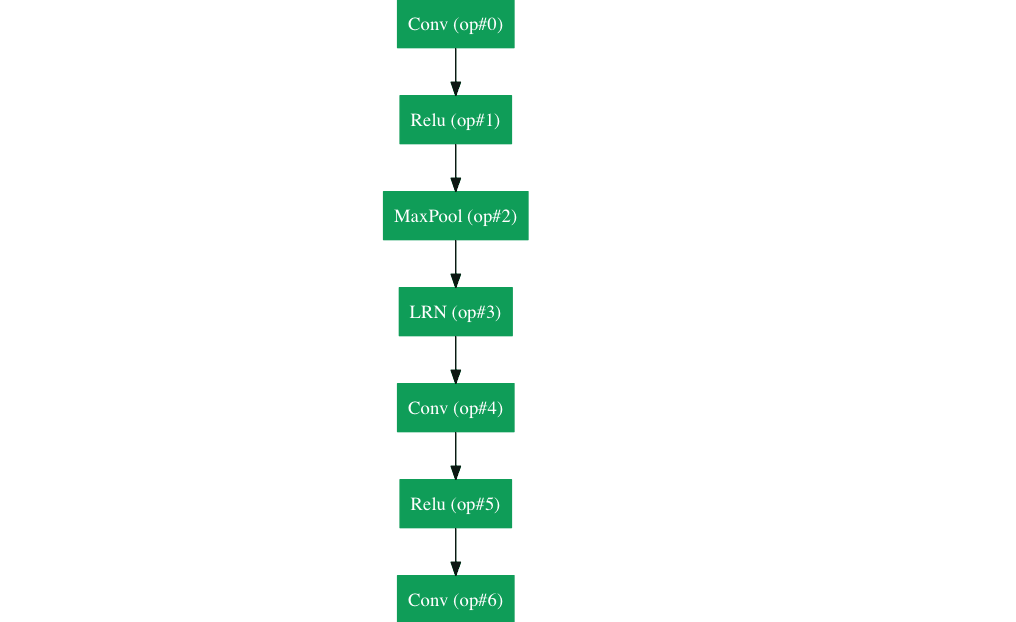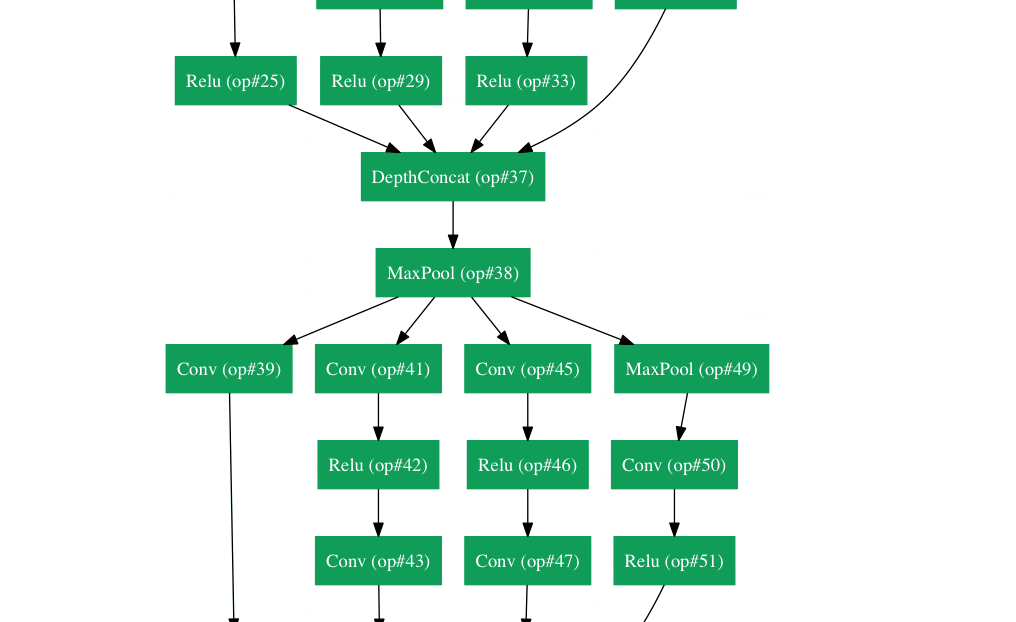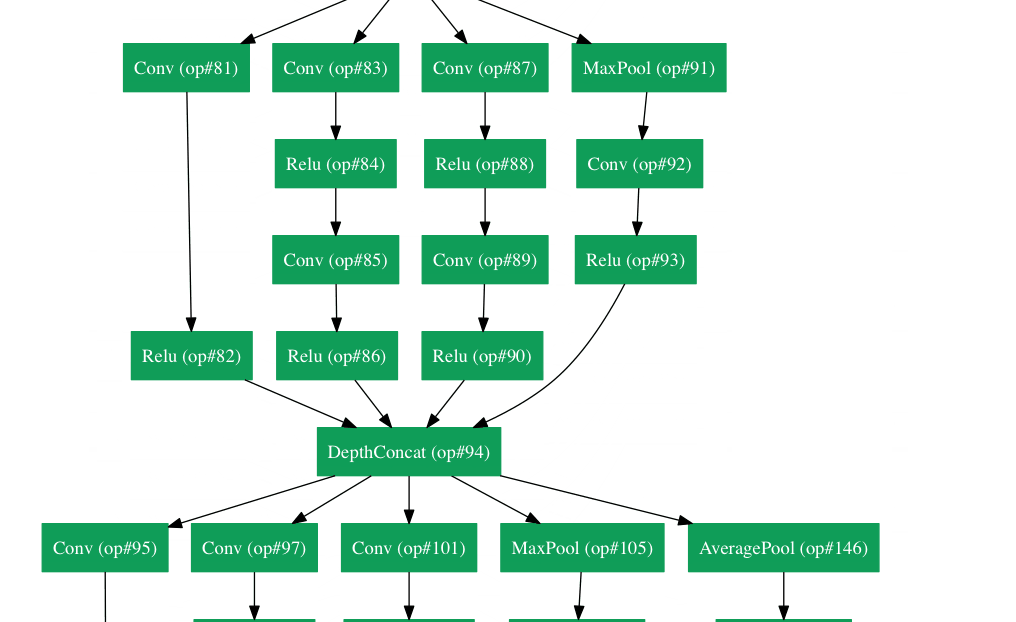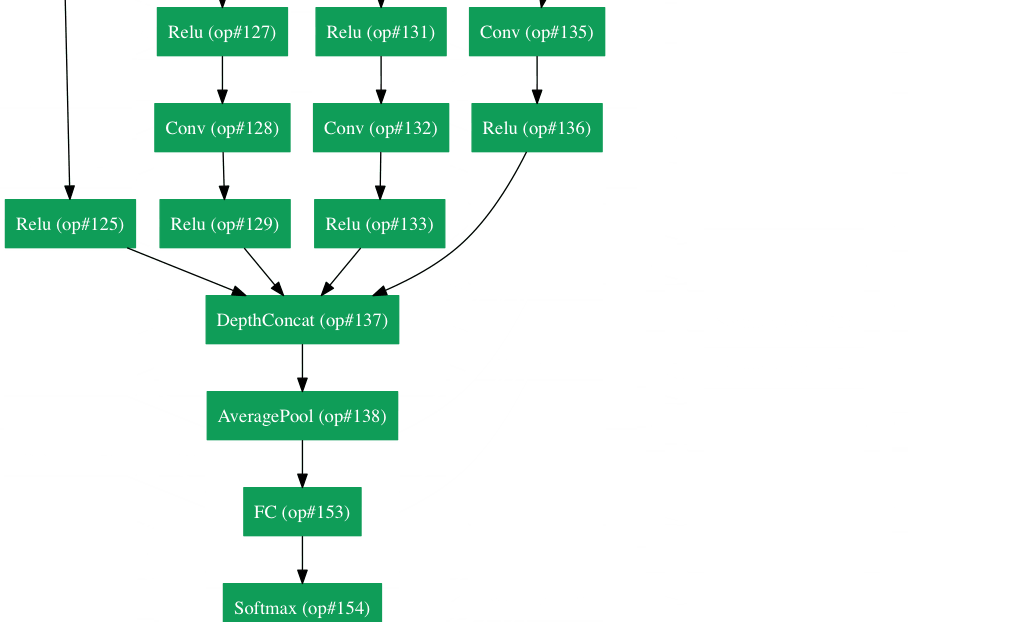
Google tenía su propia arquitectura de red neuronal que ganó el desafío de Imagenet en 2014. Lo que se puede ver en un gif aquí con más detalle .
{kind=link}
¿Cómo implementar el tuyo?
En estos días hay una variedad de marcos de aprendizaje profundo que le permiten especificar qué función matemática desea utilizar, qué arquitectura para sus funciones y qué función de pérdida usar para la capacitación. Dado que la capacitación de un modelo de este tipo es muy intensiva en términos de computación, la mayoría de estos marcos generan código optimizado para cualquier hardware que pueda tener. Algunos de los marcos famosos son: