31 lines
2.9 KiB
Markdown
31 lines
2.9 KiB
Markdown
---
|
|
title: Gradient Descent
|
|
localeTitle: Descenso de gradiente
|
|
---
|
|
## Descenso de gradiente
|
|
|
|
El descenso de gradiente es un algoritmo de optimización para encontrar el mínimo de una función. En el aprendizaje profundo, este algoritmo de optimización es muy útil cuando los parámetros no pueden calcularse analíticamente.
|
|
|
|
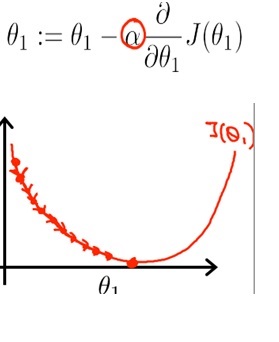 Lo que quiere hacer es actualizar repetidamente el valor del parámetro theta hasta que minimice el valor de la función de costo J (θ) cerca de 0;
|
|
|
|
### Tasa de aprendizaje
|
|
|
|
El tamaño de un paso se llama la tasa de aprendizaje. Una mayor tasa de aprendizaje hace que la iteración sea más rápida, pero podría sobrepasar el mínimo global, el valor que estamos buscando. Por otro lado, podríamos evitar este exceso al disminuir la velocidad de aprendizaje; pero tenga en cuenta que cuanto menor sea la velocidad de aprendizaje, más computacionalmente se vuelve. Esto podría prolongar el cómputo innecesariamente, o puede que no llegue al mínimo global por completo.
|
|
|
|
### Característica de escalado
|
|
|
|
Un problema de aprendizaje profundo requeriría que uses múltiples funciones para generar un modelo predictivo. Si, por ejemplo, si está construyendo un modelo predictivo para el precio de la vivienda, tendría que lidiar con características como el precio mismo, la cantidad de habitaciones, el área del lote, etc. Y estas características pueden diferir mucho en el rango, como por ejemplo, mientras que el lote El área podría estar entre 0 y 2000 pies cuadrados, las otras características, como el número de habitaciones, estarían entre 1 y 9.
|
|
|
|
Aquí es donde el escalado de características, también llamado normalización, es útil para asegurarse de que su algoritmo de aprendizaje automático funcione correctamente.
|
|
|
|
### Pendiente de gradiente estocástico
|
|
|
|
Los problemas de aprendizaje automático generalmente requieren cálculos sobre un tamaño de muestra en millones, y eso podría ser muy computacional.
|
|
|
|
En el descenso de gradiente estocástico, actualiza el parámetro para el gradiente de costo de cada ejemplo, en lugar de la suma del gradiente de costo de todos los ejemplos. Podría llegar a un conjunto de buenos parámetros más rápido después de solo unos pocos pasos a través de los ejemplos de capacitación, por lo que el aprendizaje también es más rápido.
|
|
|
|
### Otras lecturas
|
|
|
|
* [Una guía para las redes neuronales y el aprendizaje profundo.](http://neuralnetworksanddeeplearning.com/)
|
|
* [Pendiente de gradiente para el aprendizaje automático](https://machinelearningmastery.com/gradient-descent-for-machine-learning/)
|
|
* [Diferencia entre la pendiente de gradiente por lotes y la pendiente de gradiente estocástica](https://towardsdatascience.com/difference-between-batch-gradient-descent-and-stochastic-gradient-descent-1187f1291aa1) |