2.0 KiB
2.0 KiB
| title | localeTitle |
|---|---|
| Gradient Descent | 梯度下降 |
梯度下降
梯度下降是用于找到函数最小值的优化算法。在深度学习中,当无法通过分析计算参数时,此优化算法非常有用。
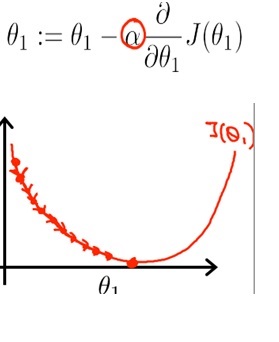 您要做的是重复更新参数theta的值,直到最小化Cost Function J(θ)的值接近0;
您要做的是重复更新参数theta的值,直到最小化Cost Function J(θ)的值接近0;
学习率
步长的大小称为学习率。较大的学习速度使迭代更快,但它可能超过全局最小值,即我们正在寻找的值。另一方面,我们可以通过降低学习率来防止这种超调;但请注意,学习率越小,计算密集程度越高。这可能会不必要地延长计算时间,或者您可能无法完全达到全局最小值。
特征缩放
深度学习问题需要您使用多个功能来生成预测模型。例如,如果您正在构建房屋定价的预测模型,则必须处理价格本身,房间数量,批量区域等功能。这些功能的范围可能非常不同,例如在批次时面积可能在0到2000平方英尺之间,其他特征如房间数量在1到9之间。
这是功能扩展(也称为规范化)派上用场的地方,以确保您的机器学习算法正常工作。
随机梯度下降
机器学习问题通常需要在数百万的样本大小上进行计算,这可能是计算密集型的。
在随机梯度下降中,您更新每个示例的成本梯度的参数,而不是所有示例的成本梯度的总和。只需几次通过训练样例,您就可以更快地得出一组好的参数,因此学习速度也更快。