5.0 KiB
| title | localeTitle |
|---|---|
| Deep Learning | 深度学习 |
深度学习
深度学习是指机器学习中的一种技术,在这种技术中,您可以在一些架构中堆叠许多人工神经网络。
对于没有经验的人来说,人工神经元基本上是某种数学函数。并且神经网络是相互连接的神经元。因此,在深度学习中,在某些架构中,您有许多数学函数堆叠在彼此的顶部(或侧面)。每个数学函数可以具有其自己的参数(例如,线y = mx + c的方程具有2个参数m和c ),这些参数需要被学习(在训练期间)。一旦学会了某项任务(比如分类猫和狗),这堆数学函数(神经元)就可以完成它对猫和狗图像进行分类的工作。
为什么这是一个大问题?
手动为一些任务提出一套规则可能非常棘手(尽管理论上可行)。例如,如果您尝试编写一组手动规则,以便对图像(基本上是一堆像素值)进行分类,确定它是属于猫还是狗,您就会明白为什么它很棘手。除此之外,狗和猫有各种形状,大小和颜色,更不用说,图像可以有不同的背景。您可以快速了解为什么编码这样一个简单的问题可能会有问题。
深度学习有助于解决这个问题,即可以自动将图像分类为猫或狗的规则。它所需要的只是一堆已经正确分类为猫或狗的图像,它将能够学习所需的规则集。魔法!
事实证明,存在许多与图像无关的问题(如语音识别),其中查找规则集非常棘手。如果已经存在大量标记数据,深度学习可以提供帮助。
如何培养深度学习模型?
训练深度神经网络(也就是我们在某些架构中安排的数学函数堆栈)基本上是一个具有大量超参数的艺术。超参数基本上是诸如使用哪种数学函数或使用哪种架构之类的东西,您需要手动识别,直到您的网络能够成功地对猫和狗进行分类。为了训练,您需要大量标记数据(在这种情况下,许多图像已经被归类为猫或狗)以及大量的计算能力和耐心!
为了训练,你提供一个具有损失函数的神经网络,它基本上说明了神经网络与正确答案的结果有多么不同。根据损失函数的值,您可以更改数学函数的参数,以便下次网络尝试对同一图像进行分类时,损失函数的值会更低。您将继续查找损失函数的值并在整个训练数据集中反复更新参数,直到损失函数值在合理的边距内。您的大规模神经网络现已准备就绪!
一些标准的神经网络架构
在过去的几年中,一些模型(即数学函数,体系结构和参数的组合)已成为某些任务的标准。例如,一个名为Resnet-152的模型在2015年赢得了Imagenet挑战赛,其中包括尝试将图像分为1000个类别(包括猫和狗)。如果您计划执行类似的任务,那么建议从这些标准模型开始,如果它们不符合您的要求,则进行调整。
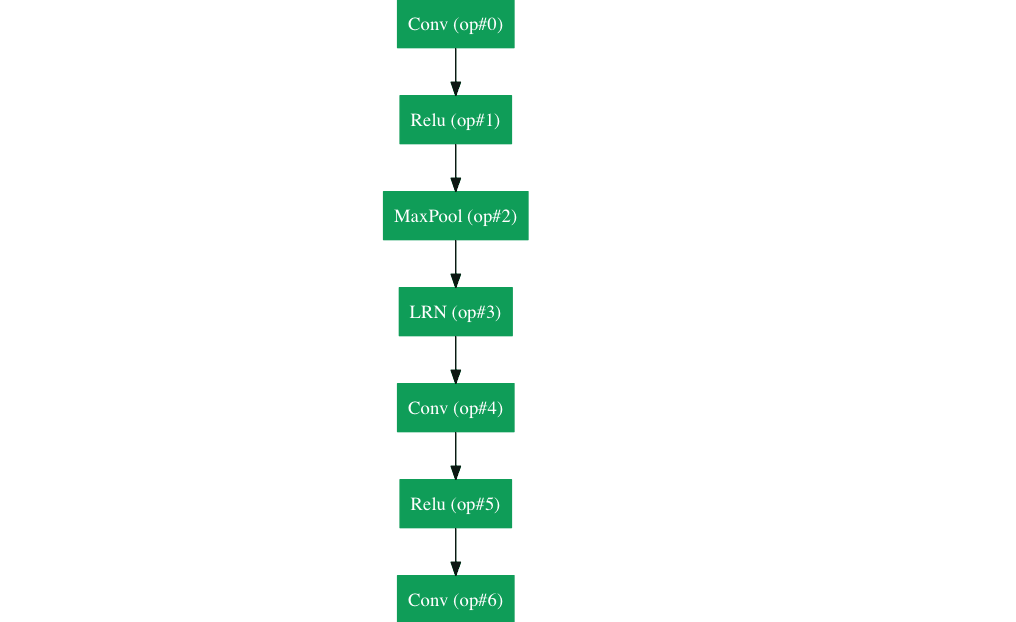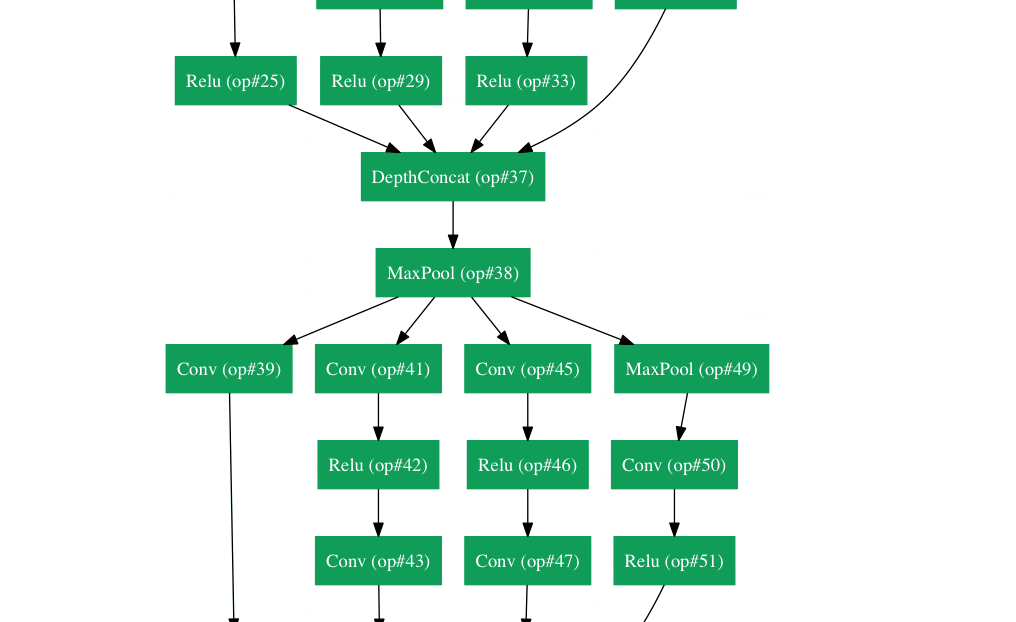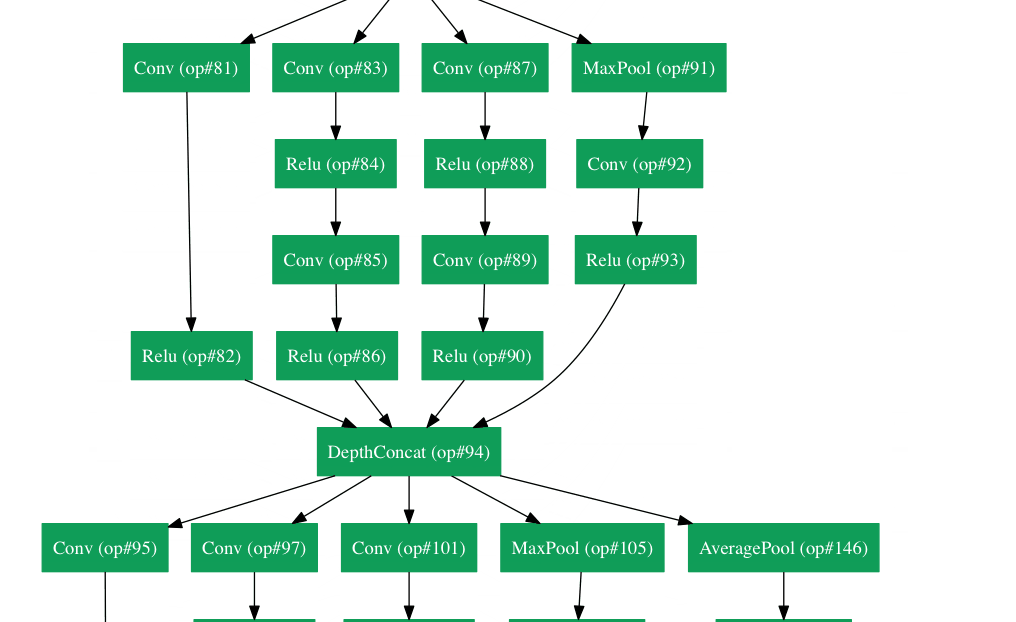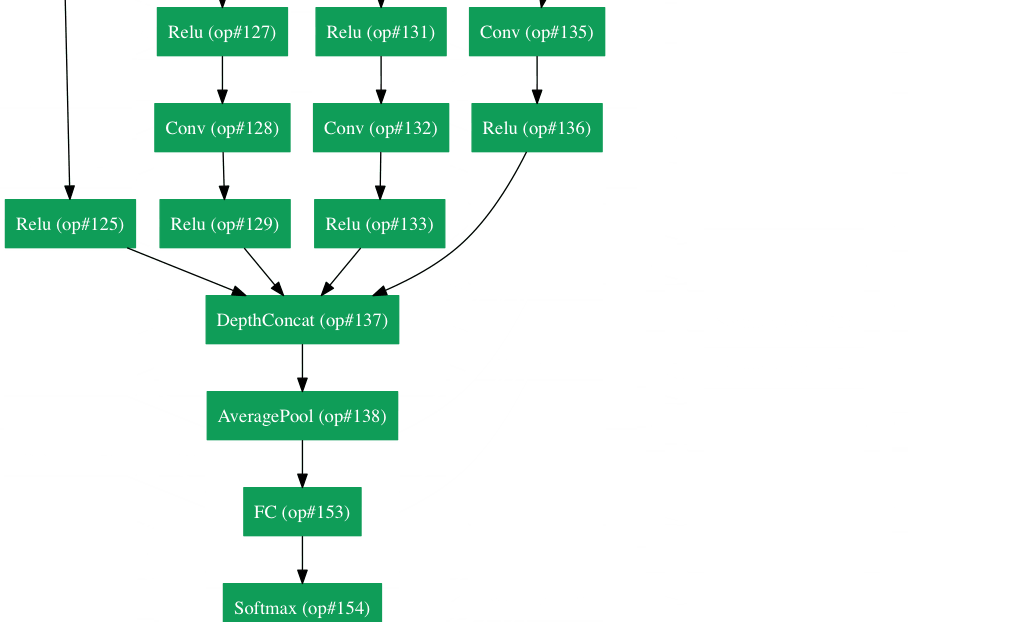
一个resnet-152模型看起来像这样(如果你不理解它,不要担心。它只是以一些有趣的方式堆叠在一起的数学函数):
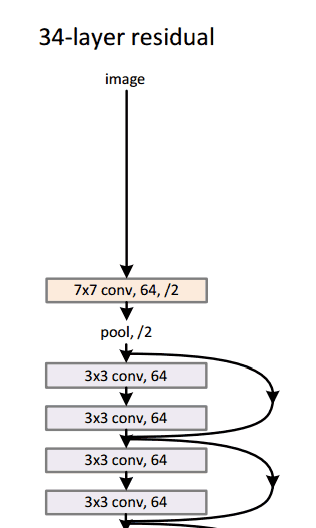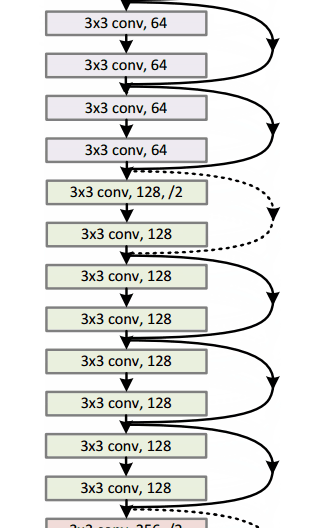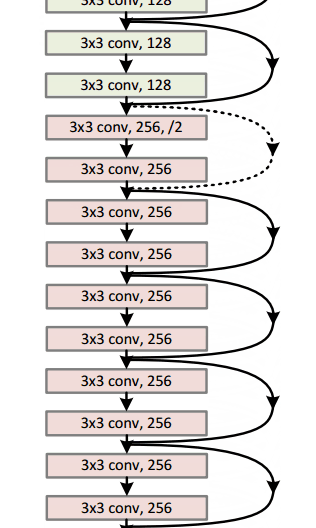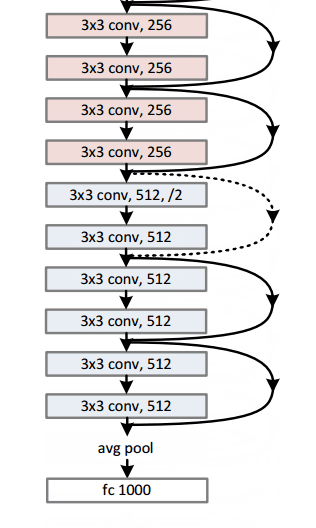
谷歌拥有自己的神经网络架构,赢得了2014年的Imagenet挑战。可以在这里更详细地看到gif 。
{kind=link}
如何实现自己的?
现在有各种各样的深度学习框架,允许您指定要使用的数学函数,函数的体系结构以及用于训练的损失函数。由于这种模型的训练计算量非常大,因此大多数这些框架都会生成针对您可能拥有的任何硬件进行优化的代码。一些着名的框架是: