31 lines
2.7 KiB
Markdown
31 lines
2.7 KiB
Markdown
---
|
|
title: Gradient Descent
|
|
localeTitle: Gradiente descendente
|
|
---
|
|
## Gradiente descendente
|
|
|
|
A descida de gradiente é um algoritmo de otimização para encontrar o mínimo de uma função. Na aprendizagem profunda, esse algoritmo de otimização é muito útil quando os parâmetros não podem ser calculados analiticamente.
|
|
|
|
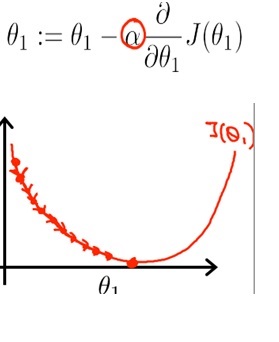 O que você quer fazer é atualizar repetidamente o valor do parâmetro theta até que você minimize o valor da Função de Custo J (θ) perto de 0;
|
|
|
|
### Taxa de Aprendizagem
|
|
|
|
O tamanho de uma etapa é chamado de taxa de aprendizado. Uma taxa de aprendizado maior torna a interação mais rápida, mas pode ultrapassar o mínimo global, o valor que estamos procurando. Por outro lado, podemos evitar esse overshooting, diminuindo a taxa de aprendizado; mas cuidado, quanto menor a taxa de aprendizado, mais computacionalmente intensivo ele fica. Isso pode prolongar desnecessariamente o cálculo ou você pode não chegar ao mínimo global.
|
|
|
|
### Escala de recursos
|
|
|
|
Um problema de aprendizado profundo exigiria que você usasse vários recursos para gerar um modelo preditivo. Se, por exemplo, você estiver criando um modelo preditivo para o preço da residência, terá que lidar com recursos como o preço em si, o número de quartos, a área do lote etc. E esses recursos podem diferir muito no intervalo, por exemplo, enquanto o lote área pode ser entre 0 e 2000 pés quadrados, os outros recursos como o número de quartos seria entre 1 e 9.
|
|
|
|
É aqui que o dimensionamento de recursos, também chamado de normalização, é útil para garantir que o algoritmo de aprendizado de máquina funcione corretamente.
|
|
|
|
### Descida Estocástica de Gradiente
|
|
|
|
Os problemas de aprendizado de máquina geralmente requerem cálculos ao longo de um tamanho de amostra em milhões, e isso pode ser muito intensivo em termos computacionais.
|
|
|
|
Na descida de gradiente estocástica, você atualiza o parâmetro para o gradiente de custo de cada exemplo e não a soma do gradiente de custo de todos os exemplos. Você poderia chegar a um conjunto de bons parâmetros mais rapidamente depois de apenas alguns passos através dos exemplos de treinamento, assim, o aprendizado é mais rápido também.
|
|
|
|
### Leitura Adicional
|
|
|
|
* [Um guia para redes neurais e aprendizagem profunda](http://neuralnetworksanddeeplearning.com/)
|
|
* [Descida de gradiente para aprendizado de máquina](https://machinelearningmastery.com/gradient-descent-for-machine-learning/)
|
|
* [Diferença entre Descida de Gradiente em Lote e Descida de Gradiente Estocástica](https://towardsdatascience.com/difference-between-batch-gradient-descent-and-stochastic-gradient-descent-1187f1291aa1) |