5.2 KiB
| title | localeTitle |
|---|---|
| Logistic Regression | Regresión logística |
Regresión logística
La regresión logística es muy similar a la regresión lineal, ya que intenta predecir una variable de respuesta Y dado un conjunto de X variables de entrada. Es una forma de aprendizaje supervisado, que trata de predecir las respuestas de datos no marcados e invisibles mediante el primer entrenamiento con datos etiquetados, un conjunto de observaciones de variables independientes (X) y dependientes (Y). Pero mientras la Regresión lineal asume que la variable de respuesta (Y) es cuantitativa o continua, la Regresión logística se usa específicamente cuando la variable de respuesta es cualitativa o discreta.
Cómo funciona
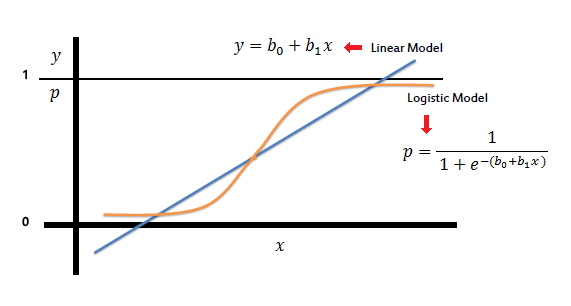
La regresión logística modela la probabilidad de que Y, la variable de respuesta, pertenezca a una determinada categoría. En muchos casos, la variable de respuesta será una binaria, por lo que la regresión logística querrá modelar una función y = f (x) que genera un valor normalizado que varía de, por ejemplo, 0 a 1 para todos los valores de X, correspondientes a Los dos valores posibles de Y. Lo hace utilizando la función logística: La regresión logística es el análisis de regresión apropiado para realizar cuando la variable dependiente es dicotómica (binaria). Como todos los análisis de regresión, la regresión logística es un análisis predictivo. La regresión logística se utiliza para describir datos y para explicar la relación entre una variable binaria dependiente y una o más variables independientes nominales, ordinales, de intervalo o de relación.
 La regresión logística se utiliza para resolver problemas de clasificación, donde la salida es de la forma y∈ {0,1}. Aquí, 0 es una clase negativa y 1 es una clase positiva. Digamos que tenemos una hipótesis hθ (x), donde x es nuestro conjunto de datos (una matriz) de longitud m. θ es la matriz parametérica. Tenemos: 0 <hθ (x) <1
La regresión logística se utiliza para resolver problemas de clasificación, donde la salida es de la forma y∈ {0,1}. Aquí, 0 es una clase negativa y 1 es una clase positiva. Digamos que tenemos una hipótesis hθ (x), donde x es nuestro conjunto de datos (una matriz) de longitud m. θ es la matriz parametérica. Tenemos: 0 <hθ (x) <1
En la regresión logística, hθ (x) es una función sigmoide, por lo tanto hθ (x) = g (θ'x). g (θ'x) = 1/1 + e ^ (- θ'x)
Nota: θ 'es θ transposición.
Función de costo
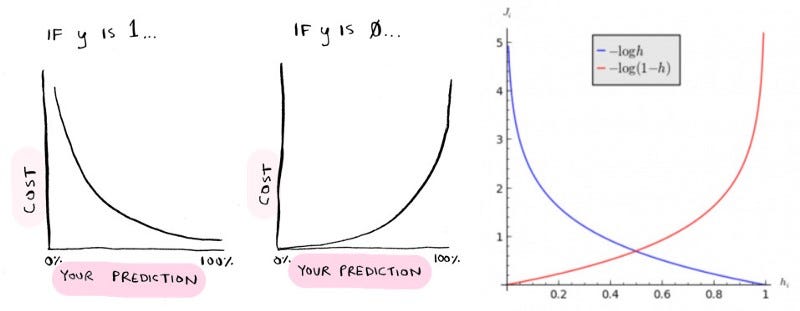
La función de costo utilizada para la regresión logística es:
J (θ) = (1 / m) ∑Cost (hθ (x (i)), y (i)), donde la suma es de i = 1 a m.
Costo (hθ (x), y) = - log (hθ (x)) si y = 1 Costo (hθ (x), y) = - log (1 − hθ (x)) si y = 0
Predicciones utilizando regresión logística:
La regresión logística modela la probabilidad de la clase predeterminada (es decir, la primera clase). Puedes clasificar los resultados dados por:
y = e ^ (b0 + b1 X) / (1 + e ^ (b0 + b1 X))
en dos clases. Al igual que la función sigmoide 0.5 se establece como el límite de decisión, todas las x para las cuales y≥0.5 se clasifican como clase A y para las cuales y <0.5 se clasifican como clase B.
Regresión logística multiclase:
Aunque verá que la regresión logística se usa generalmente en el caso de la clasificación binaria, también puede usarla en el caso de la clasificación en varias clases de la siguiente manera:
Método uno contra uno:
Aquí se crea un clasificador para cada clase por separado y el clasificador con la puntuación más alta se considera como salida.
uno contra todo método:
Aquí se hacen múltiples clasificadores binarios (N * N (N-1) / 2 donde N = no. De clases) y luego, al comparar sus puntajes, se obtiene el resultado.
Aplicaciones de regresión logística:
- Clasificar el correo como spam o no spam. 2) Para determinar la presencia o ausencia de cierta enfermedad como el cáncer según los síntomas y otros datos médicos. 3) Clasificar imágenes basadas en datos de píxeles.
Suposiciones de regresión logística
La regresión logística binaria requiere que la variable dependiente sea binaria. Para una regresión binaria, el nivel de factor 1 de la variable dependiente debe representar el resultado deseado. Solo deben incluirse las variables significativas. Las variables independientes deben ser independientes entre sí. Es decir, el modelo debe tener poca o ninguna multicolinealidad. Las variables independientes están relacionadas linealmente con las probabilidades de registro. La regresión logística requiere tamaños de muestra bastante grandes.
Más información:
Para leer más para construir la regresión logística paso a paso: